Some people keep insisting that AI (which is a term I try to avoid, here I am calling them VLMs) cannot be good sources of alt text. My belief is that they can, even if it’s not as good as a human written one, it can be made to be better than one that’s never written, or form a good base for someone to edit. Both of those would be a net positive. I personally want to write more alt text but often don’t, and felt that something like this could be a good base for me to just read and confirm, or edit and push forward.
I tested this first on witchsky.app where I wasn’t impressed (edit: I believe they adjusted to the prompt I suggested), the result was too distracted and too verbose, I suspected this was a prompt issue so I added a feature to it (not upstreamed, but an open issue) to change the prompt.
My belief was that VLM generated alt text so far been bad not because it has to be bad, but because there’s not been enough thought put into it. So I did a wee bit of experimentation with vision-language models, some iterative tweaking, and (spoiler alert) I think it came out pretty good for an hour’s worth of effort. This isn’t meant as a “hey it’s perfect”, but rather as a “hey, there’s promise here as accessibility tech”.
(I also have the aim of using open weight models for this experiment, both for cost, and as I believe that this can be done fully offline in the future.)
FYI
I have providers that may train on inputs excluded on openrouter (you can set that here), and my training settings are off on claude as well (you can set that here). The sample data is not going to be trained on solely because of this experiment.
ground truth collection
I had claude code write a script to collect images with alt text from the bluesky firehose (a websocket that just gives you all the events, basically), with a filter on very short alt text, nsfw posts, selfies and post language english.
I let that script collect ~120 pictures, then deleted ~60 of them that had bad alt text, and was left with 68 pictures. Some that I removed were hyper-specific (required knowing character names), most had bad alt text (spam or just “a post of x” type thing), one was untagged porn.
prompt and model tweaking
I gave claude the list of most popular image-input models on openrouter, told it to exclude free models and non-open weight ones (especially openai/anthropic/google/xai).
It tested mistralai/mistral-small-2603 (mistral small 4), qwen/qwen3.5-122b-a10b, qwen/qwen3.5-27b, moonshotai/kimi-k2.5, bytedance-seed/seed-2.0-lite and qwen/qwen3.5-35b-a3b. I also had it test gemini-2.5-flash-lite as that’s what witchsky.app uses. Later I also did tests with google/gemma-4-31b-it and google/gemma-4-26b-a4b-it as well.
I contemplated on using an LLM judge vs using more traditional metrics, but as we’re working with fuzzy values, I stuck to an LLM judge.
For the LLM judge I picked mistralai/mistral-small-2603 for no reason other than “I like mistral”. Metrics to rate were Accuracy, Completeness, Conciseness, Accessibility, rated out of 5.
The full prompt for judge
System prompt:
You are an expert accessibility evaluator. You will be given a ground truth alt text (written by a human) and a machine-generated alt text for the same image. Score the generated alt text on these criteria, each from 1 (poor) to 5 (excellent):
- Accuracy - Does the generated text correctly describe the image content? Use the ground truth as reference for what the image contains. Penalize hallucinated or incorrect details.
- Completeness - Does it capture the important elements present in the ground truth? It doesn’t need to match exactly, but should cover the key content.
- Conciseness - Is it an appropriate length? Alt text should be informative but not excessively verbose. 1-2 sentences for simple images, up to a short paragraph for complex ones.
- Accessibility - Would this be genuinely useful to a screen reader user? Does it convey meaning and context, not just list objects?
Respond with ONLY this JSON, no other text:
{"accuracy": <1-5>, "completeness": <1-5>, "conciseness": <1-5>, "accessibility": <1-5>, "reasoning": "<1-2 sentences>"}User message:
Ground truth alt text
{ground_truth}Generated alt text{generated}Score the generated alt text.
Overall, qwen-122b and 27b were pretty close, but 122b did better and was almost identical in cost on openrouter, so we proceeded with that (I suspect same prompt on a locally hosted 27b would be also pretty good). We then tweaked the prompt to perform the best against the weaker cases, and that got us to a prompt that strikes a very good balance of descriptiveness, minimal hallucinations and length. Aim was to get good results for both regular pictures and for pictures of text, and to minimize hallucinations.
My suggested model and prompt
My current recommendation is
qwen/qwen3.5-122b-a10bwith a prompt of “Write alt text for this image. Be concise — 1-2 sentences for simple images. If the image contains readable text, transcribe it rather than describing it. Only describe what you can clearly see; do not guess at names or details.”.
That got a score of Accuracy: 4.03, Completeness: 3.99, Conciseness: 4.18, Accessibility: 3.99, for an overall score of 4.04 (out of 5). All that experimentation cost me $3.359 of API fees on openrouter (that’s 3 dollars, not 3359 dollars).
Each alt text I generate costs me roughly $0.0024, so $5 of credits pay for roughly 2083 alt texts. That’s a lot!
Due to the nature of open weight models, you could also run this model locally on a server or a computer. As open weight models get better, we might be able to do this fully locally on the device as well, which is pretty exciting. Being able to do this on-device fully offline would be great.
result examples
Overall I’m pretty happy with it. I think each example I’ve seen from it so far would only require minimal tweaking to be useful. I do genuinely think that if bluesky attached these by default, it’d be significantly better than nothing.
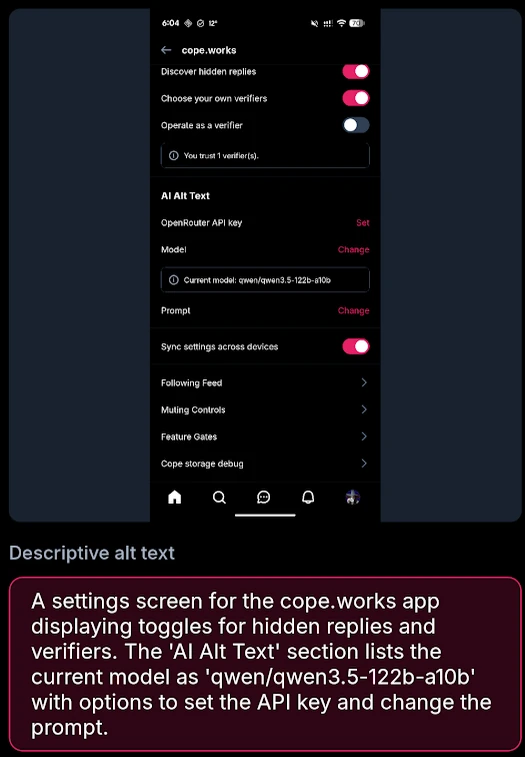
These screenshots are from cope.works, a friend’s bluesky client where we also added support for auto-generated alt text. I believe witchsky.app is also adapting to my suggested prompt now, albeit with gemma 4 as the default (which performs worse). FWIW, here’s what the UI for it looks like within the alt text view:
As a note, I’m trying to intersperse the good and bad cases within the results here. No point in overselling you something, I’m moreso interested in showing what works and what doesn’t.
You can play it yourself here by inserting your own openrouter api key. I also have a tech demo fork of tusky here with the alt text generation functionality added.
memes
These are generally fine, but generally subjects aren’t named. For really complex ones, it may mix up details.
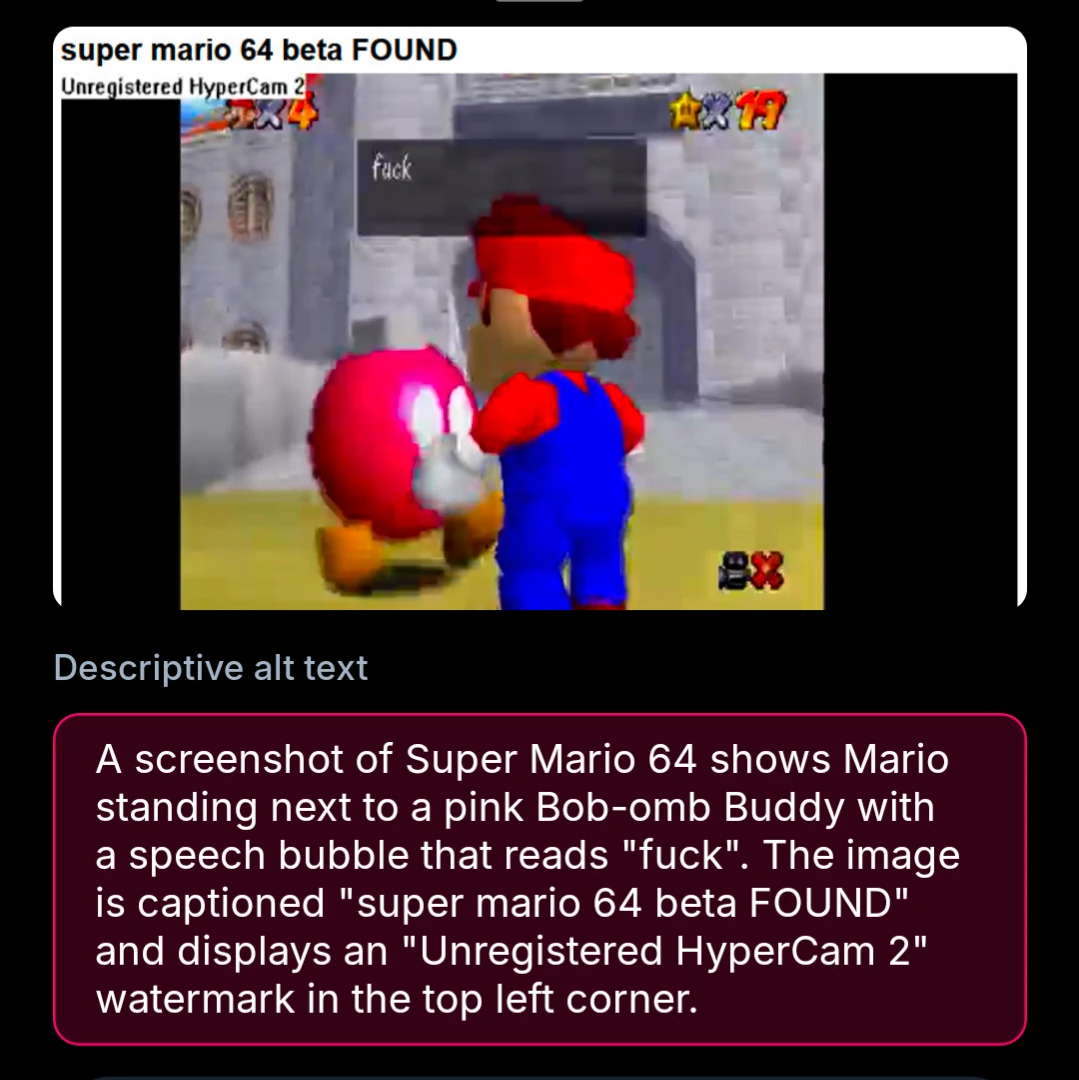
Perfect.

This is pretty accurate, except it doesn’t try to guess Scott the Woz. I’d just change “a smiling young man wearing glasses” to “Scott the Woz, a Nintendo YouTuber”.

Pretty accurate, except the smaller figure is not pointing to the bag. I’d add the artist name and note that the smaller figure is a dog.

Beautiful. I never thought of it as being below it, but I suppose that’s true.

Accurate, but missing that it’s a modified copy of the subway meme.

This is a tough one. It tried its best, but main/side track terminology is a bit confusing (I think it is true that tram would turn to the 1 person by default based on the lines on the tracks), and the merged track isn’t on an isolated separate track on the right.
screenshots and diagrams
These are pretty good. It can miss points of diagrams or be unsure what to focus on with screenshots when there’s too much happening.
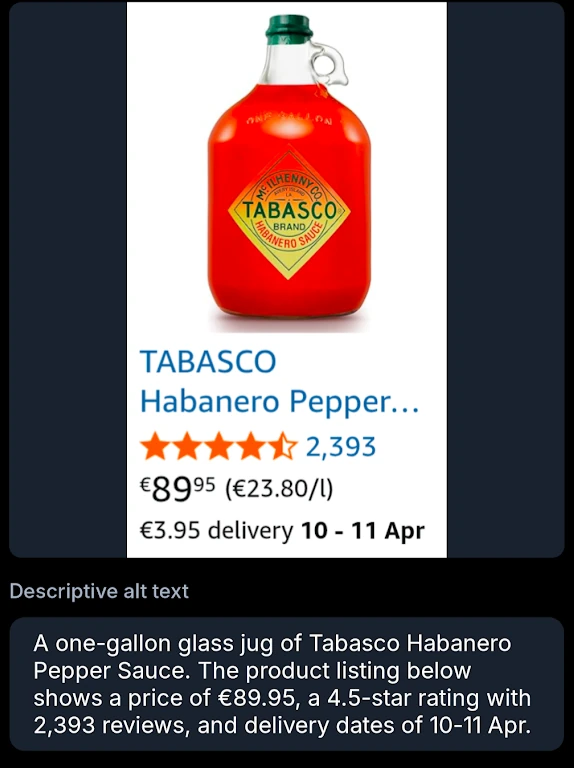
Accurate! It even correctly deduced that it’s a gallon from the liter price.
Accurate. It doesn’t know what to look for, so it’s just guessing that the middle of the screen is the most important part.
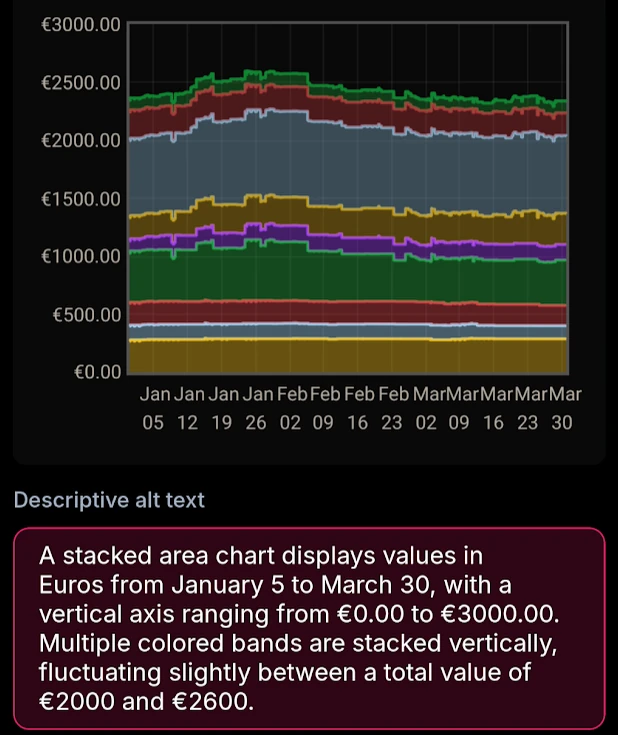
Here it primarily lacks context, so it’s just guessing, but it’s mostly accurate. It’s also between 2300-2400EUR and 2600EUR, not 2000EUR, so if using this I’d manually tweak that at least.
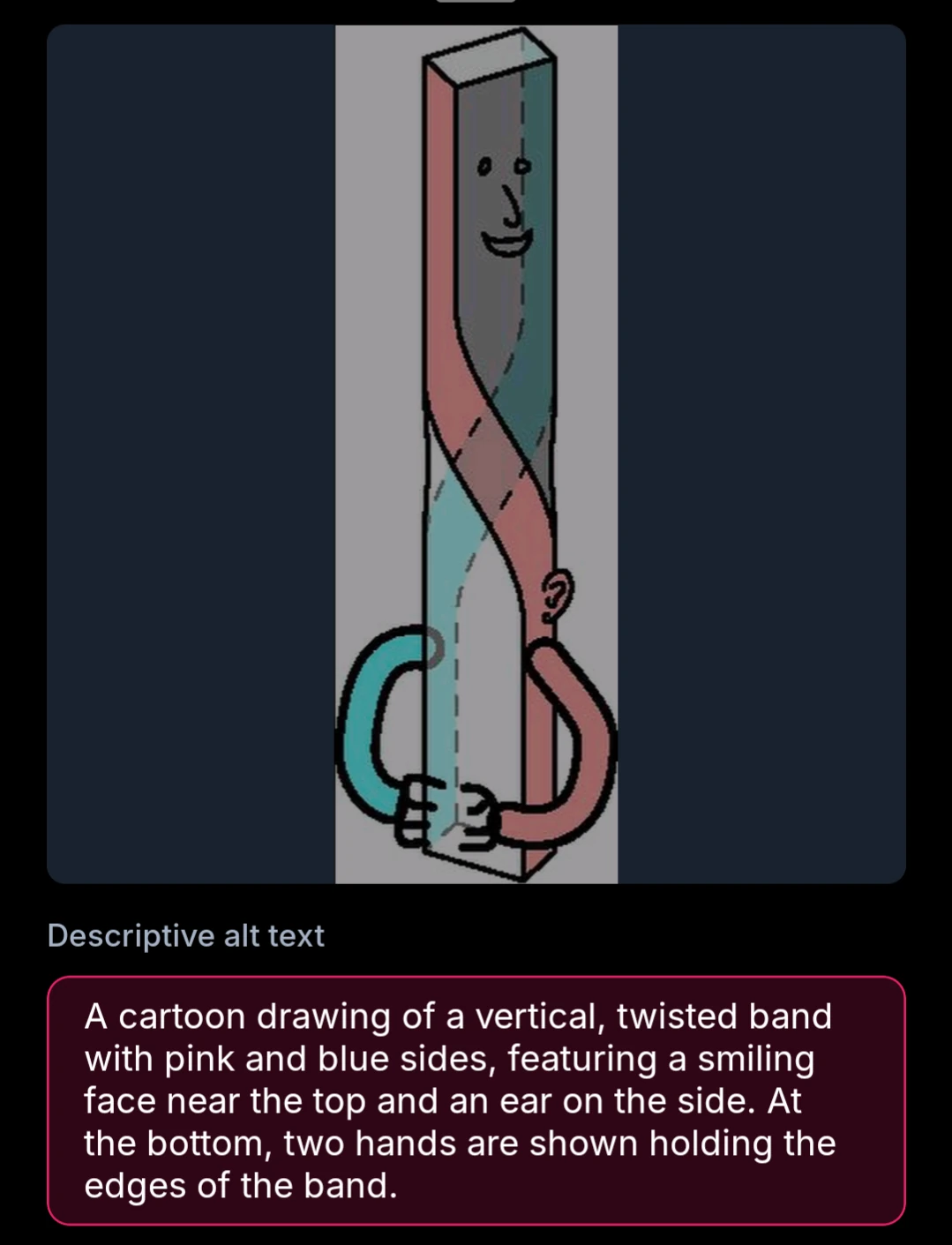
Correct, though it’s not quite sure what’s going on in it. That’s a beautiful drawing from the Axial Twist Theory page on wikipedia.
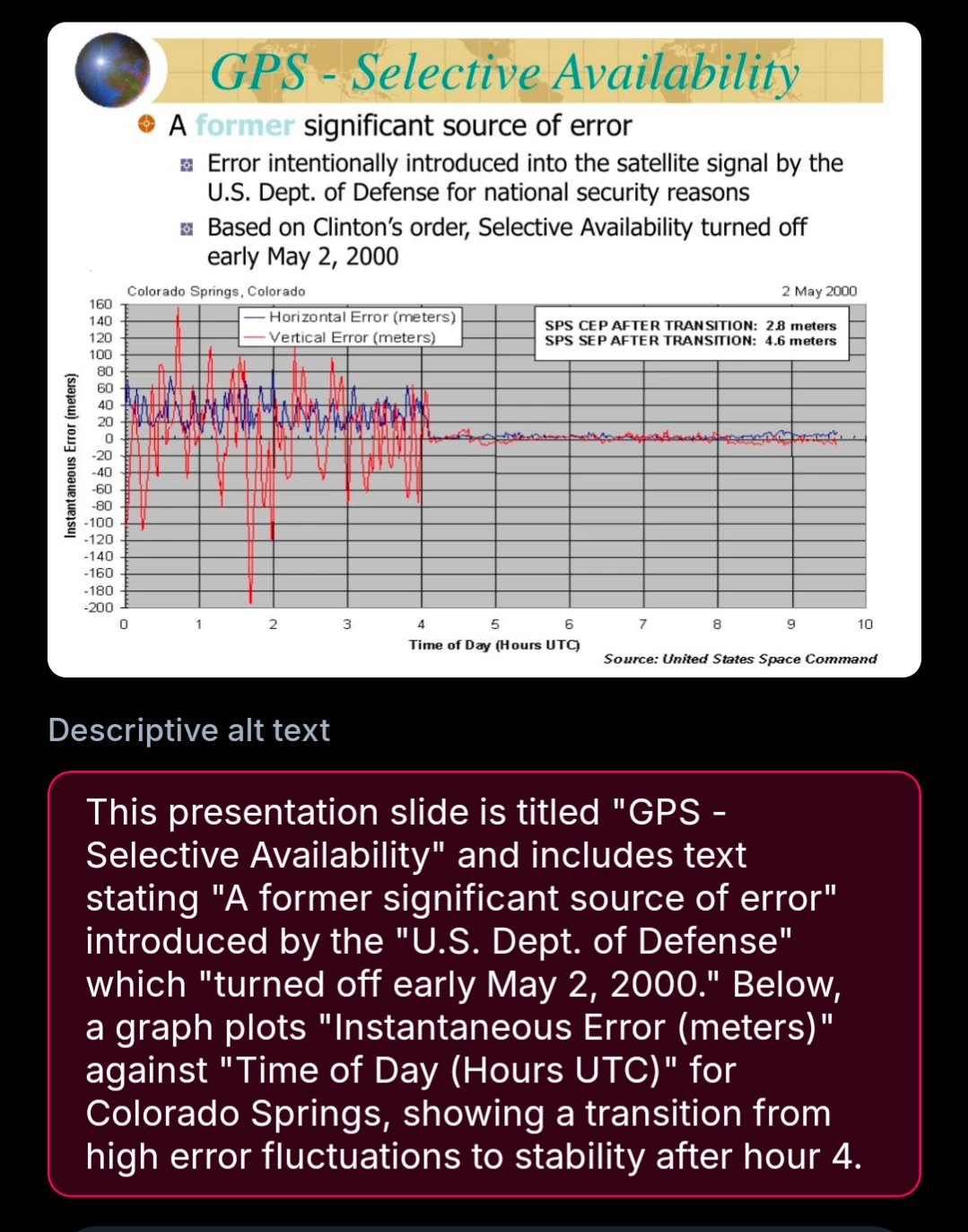
Pretty accurate, though I’d mention the degree to which the instability was occurring (reduced from ~100m to ~5m).
irl pics
Bit too focused on text. Otherwise pretty good!

As this is Qwen (a chinese model), which tends to get uppity when you ask questions that aren’t quite in the interest of CCP, I tested it with tank man. Happy to say it did great! I’d maybe caption it “tank man” also, and remove the part about the street lamp (never even noticed those were there).

Correct.

No reference picture for this one for hopefully understandable reasons. Too much focus on text, otherwise really good.

It’s great at reading text that’s barely visible until the point when it might actually matter. Amusing. That’s a bottle of Chocomel, picture taken in Amsterdam next to Amsterdam Centraal station. Text is otherwise accurate, I’d tweak those.

Not great, but it clearly tried. The slogan is cut off but it’s claiming that the cut-off slogan is the slogan. I think it’s also being loaded out of the aircraft carrier, not into.
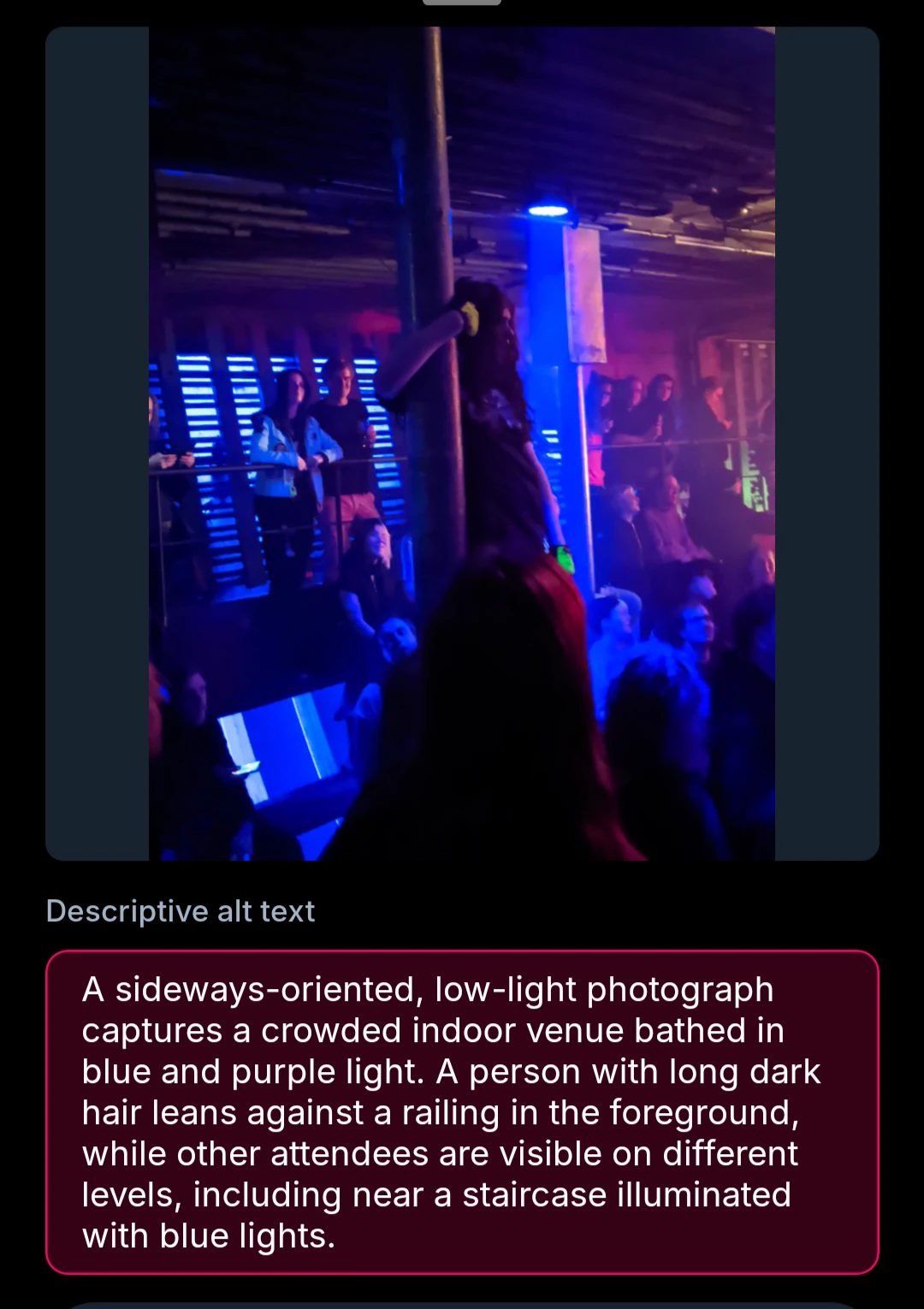
Not great, it does cover the topic, but it doesn’t really have a good chance to describe that that’s the artist (Femtanyl) that’s standing within the crowd, as it simply doesn’t know. This will always be a limitation of this approach.

Correct, except I’m not sure if it is a metal bowl, I’d just drop metal. As a courtesy I’d include a translation also.

Correct. I’d add a tiny mention that it’s Hamburg Messe, and then it’s perfect.
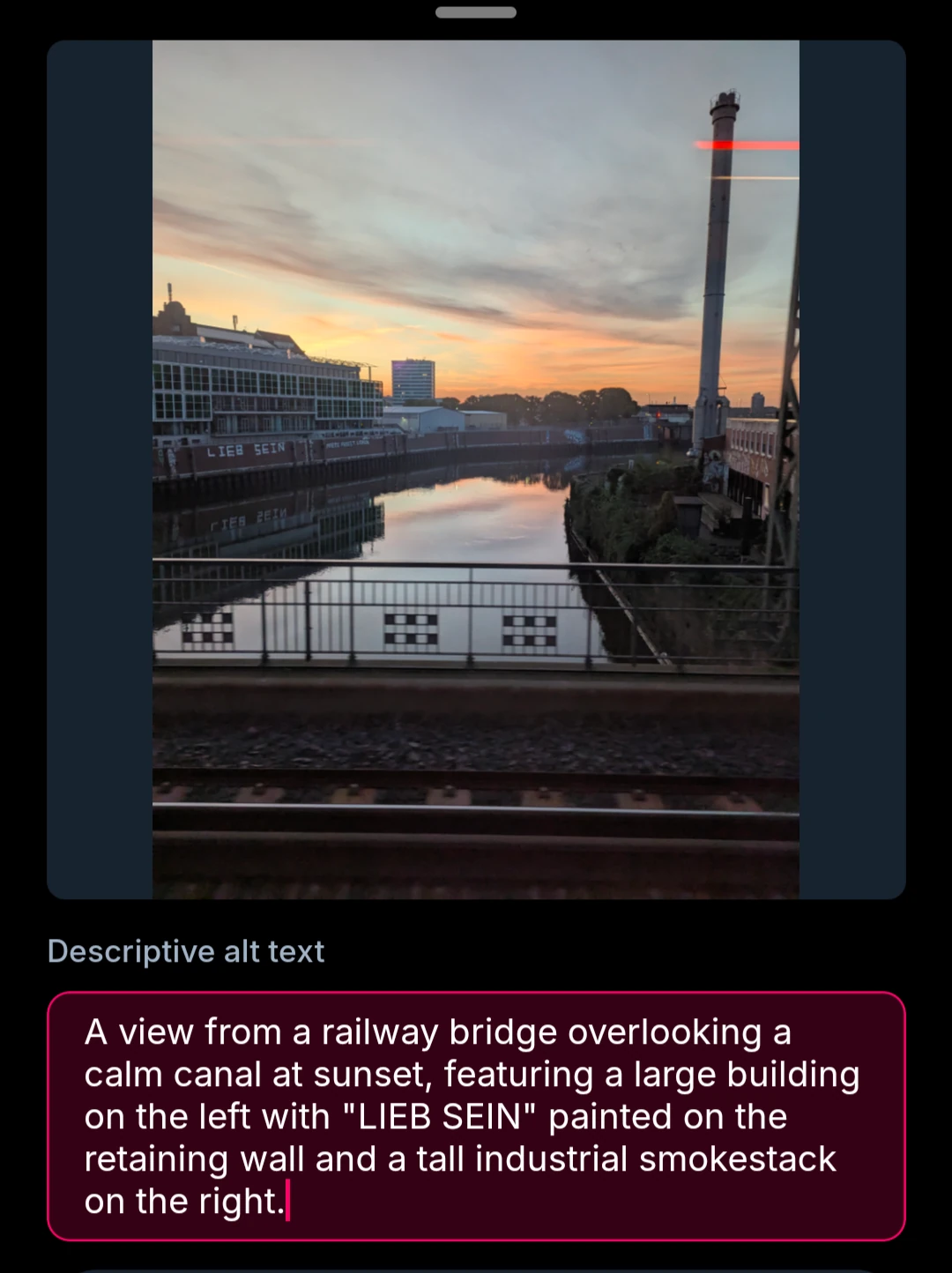
Bit too much focus on the text. One complaint was that it’s not great at describing skies, I’d agree with that, though it’s likely to be a prompt issue.

Correct.

Correct, potentially too much focus on the text. That is the Heinrich Hertz Tower viewed from Hamburg Messe, I’d mention that.

Pretty accurate, the outer cuts aren’t mentioned, and it’s a bit too text focused (the BRM LASERS text is barely visible!).

Accurate. This is Madrid, I’d note that.

Accurate. This is next to Oodi Public Library, I’d note that.

Accurate.

I’d replace “An older man with white hair and glasses” with “Bernie Sanders” and clarify that it’s a phone on a mic stand that he’s speaking to, not just a standalone mic.

Accurate, but it’s missing the important points: The leftmost 2 are the same exact product, but one is much smaller despite the same solder weight, it’s a redesigned package. Rightmost is a 100g, it’s not visible, but it’s clearly smaller than the rest (so mentioning the spec might be irresponsible).

Pretty good, but it’s a shoulder bag, not a backpack. Maybe I’d clarify that it’s a plane floor and also what the lanyard means.
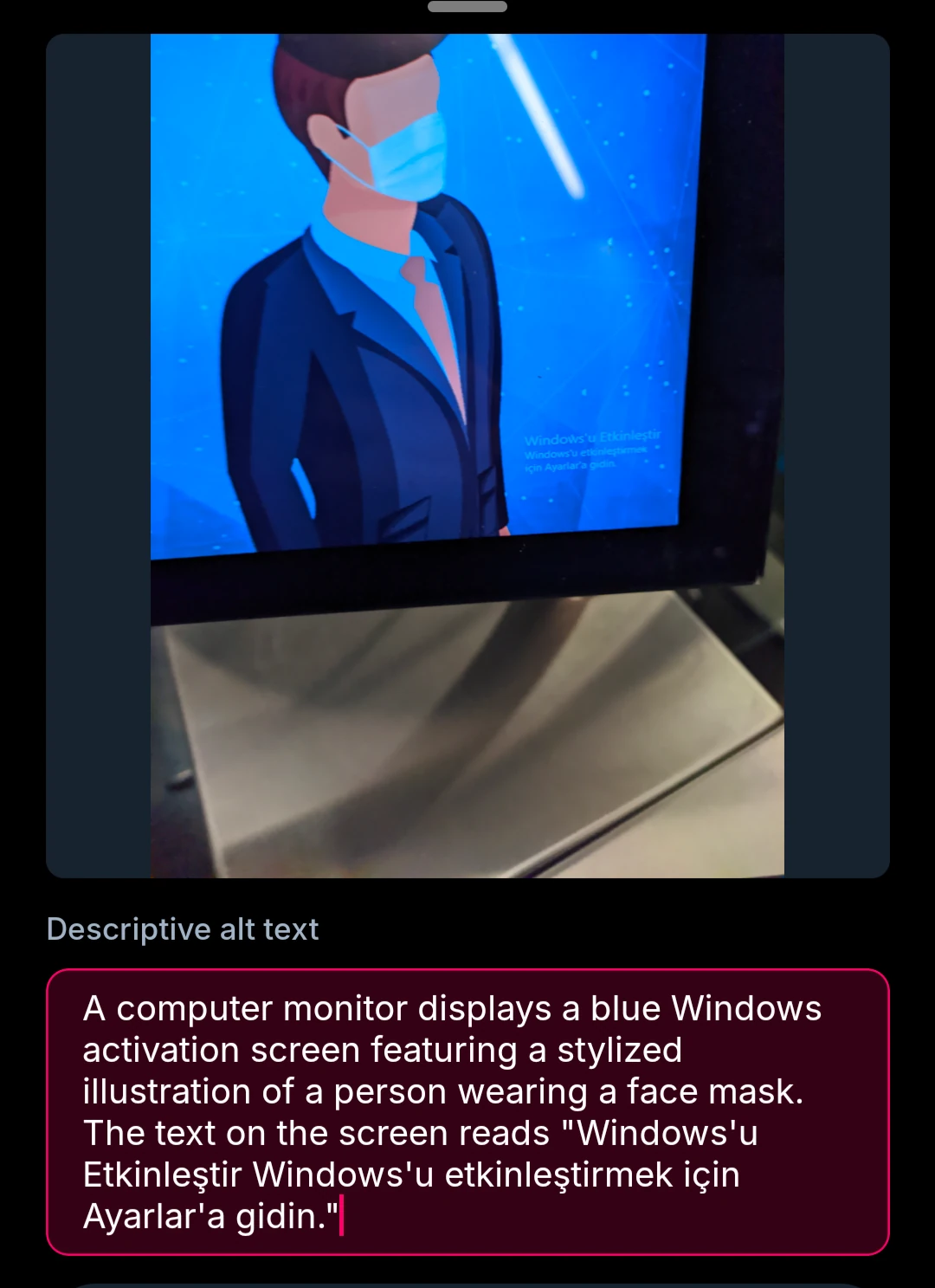
Accurate, but lacking context that this is a border crossing gate. I’d also include a translation, though the blunder is probably parseable regardless of language.

Accurate. I’d note down that it’s Jacksfilms, a youtuber, and that it’s a meme, but pretty good regardless.
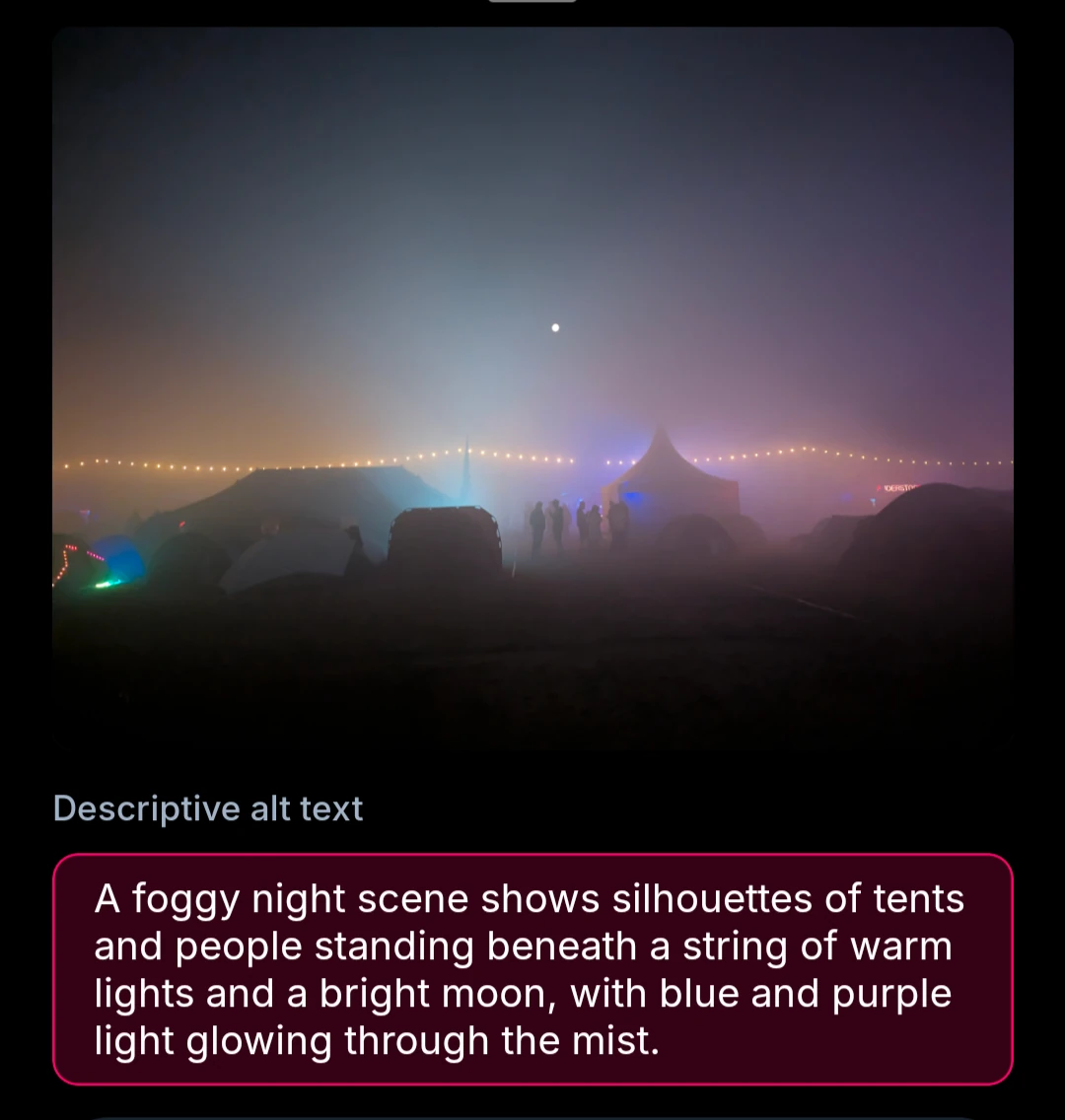
Accurate. I’d just note that it’s WHY2025 camp in Netherlands.
video games
Same as irl pics, kind of too focused on text, but otherwise pretty good! All following screenshots are from Alan Wake 2.

Pretty good! I wouldn’t necessarily capitalize “MAKES THE DREAMWORK”.

Would be cool if it followed the arrow order, but it’s correct.

Bit too focused on text, +2 is the correct focus, but pistol info is a bit silly to include. I’d remove it before sending this post.

Correct. It doesn’t mention the sheer extent of how much text there is, but the text it reads is correct, and does include one of the more key passages used within the game.