This is a hot topic :)
These notes are primarily around claude code, and don’t touch on social, economic or ecological impacts. That’s not because I’m ignoring them, but this post is supposed to be primarily about “how to get work done without sticking a stick in the bike’s wheel”. I’ll write on those eventually.
{kind=link}
Key reading: But what does Oxide think?

I’m a big fan of Oxide Computer’s RFD on careful LLM usage. They put my feelings around this better than I do.
I like the following part from “LLMs as programmers”:
Wherever LLM-generated code is used, it becomes the responsibility of the engineer. As part of this process of taking responsibility, self-review becomes essential: LLM-generated code should not be reviewed by others if the responsible engineer has not themselves reviewed it. Moreover, once in the loop of peer review, generation should more or less be removed: if code review comments are addressed by wholesale re-generation, iterative review becomes impossible.
and the entirety of “LLMs as writers”:
While LLMs are adept at reading and can be terrific at editing, their writing is much more mixed. At best, writing from LLMs is hackneyed and cliché-ridden; at worst, it brims with tells that reveal that the prose is in fact automatically generated.
What’s so bad about this? First, to those who can recognize an LLM’s reveals (an expanding demographic!), it’s just embarrassing — it’s as if the writer is walking around with their intellectual fly open. But there are deeper problems: LLM-generated writing undermines the authenticity of not just one’s writing but of the thinking behind it as well. If the prose is automatically generated, might the ideas be too? The reader can’t be sure — and increasingly, the hallmarks of LLM generation cause readers to turn off (or worse).
Finally, LLM-generated prose undermines a social contract of sorts: absent LLMs, it is presumed that of the reader and the writer, it is the writer that has undertaken the greater intellectual exertion. (That is, it is more work to write than to read!) For the reader, this is important: should they struggle with an idea, they can reasonably assume that the writer themselves understands it — and it is the least a reader can do to labor to make sense of it.
If, however, prose is LLM-generated, this social contract becomes ripped up: a reader cannot assume that the writer understands their ideas because they might not so much have read the product of the LLM that they tasked to write it. If one is lucky, these are LLM hallucinations: obviously wrong and quickly discarded. If one is unlucky, however, it will be a kind of LLM-induced cognitive dissonance: a puzzle in which pieces don’t fit because there is in fact no puzzle at all. This can leave a reader frustrated: why should they spend more time reading prose than the writer spent writing it?
This can be navigated, of course, but it is truly perilous: our writing is an important vessel for building trust — and that trust can be quickly eroded if we are not speaking with our own voice. For us at Oxide, there is a more mechanical reason to be jaundiced about using LLMs to write: because our hiring process very much selects for writers, we know that everyone at Oxide can write — and we have the luxury of demanding of ourselves the kind of writing that we know that we are all capable of.
So our guideline is to generally not use LLMs to write, but this shouldn’t be thought of as an absolute — and it doesn’t mean that an LLM can’t be used as part of the writing process. Just please: consider your responsibility to yourself, to your own ideas — and to the reader.
Code review
Anything I put out there has my name on it: I’m not paid for raw lines of code, but rather for being able to provide a service of building software that works towards a goal while maintaining a reasonable level of tech debt at any given time. Otherwise I’d be making 90EUR/mo instead of however much I make. LLMs provide a way to speed up code output and new ways of understanding challenges and achieving solutions, but where possible, instead of replacing yourself with it, integrate it into your workflow while keeping quality to at least your previous standards.
As such, anything that’ll be reviewed by others should be first reviewed by me. If I’m only going to skim it because it’s an unimportant script that’ll be run once or twice, I try to make sure that the other person reviewing would also only skim it, so that I don’t subject them to a greater review burden than I.
LLMs make it very easy to take the easy route and just accept a “good enough” solution. I do tend to be fine with these on personal projects, but never on professional ones. It’s a PR that would’ve taken me an hour before, I spent 10 minutes engineering it, claude hammered it out in 10 minutes and the result is “just alright”? Sounds like I have 40 minutes of time budget to make it at least as good as I would’ve wanted to make it.
Documentation

I strongly believe that using LLMs to generate and maintain documentation is a waste of time and tokens if you also have access to the code.
They’ll produce very verbose documentation by default, or if you prompt them not to, they might miss important details. The larger a document they have to maintain, the more little bits will be forgotten to be updated. Yes, even LLMs make mistakes ;)
It is (or used to be?) important to “write the fucking manual”, but let’s not forget that the original is “read the fucking manual”. Subjecting people to a massive document is not the way to go.
Load up a codebase and ask an LLM questions about what you want to know. (see Sandboxing especially for third party repos) This way you can just learn about the feature, code path, function, etc you want to learn about, and you can ask to make more or less details. You can ask follow-up questions.
Perhaps boldly: Don’t “write the fucking manual”. (There are cases where it makes sense, but it’s a more limited subset now.)
Sandboxing
Sandbox. /sandbox. do it.
- It reduces the need for approvals.
- It reduces the risk of it nuking your production database, or releasing the hypnodrones.
- It does confuse it somewhat when it fails to write something, but it can often find its way around it. There can be bugs that further confuse the model, those do suck.
Go enable notifications while at it, so that you can multi-track-drift without --dangerously-skip-permissions. I’d love to also suggest using the claude app with /remote-connect but I’ve not had it work well for me, esp with permission configs.
{kind=link}
You can be even smarter and just run it in a docker container or qemu (example project, blog post about it). Then you don’t even have to worry about the shortcomings of sandboxing (and have a whole new series of problems to worry about ;) ).
(Not) Over-complicating things
This is a good blog post by Tim Kellogg arguing against using Plan Mode: https://timkellogg.me/blog/2026/03/08/plan-mode
I don’t fully agree with it, but my suggestion would be to always keep in mind the future proofing of code. I don’t use plan mode for small changes, and I don’t accept grandiose plans built by LLMs (but somehow, the way I prompt them doesn’t seem to get them to offer me that all that much anyways).
Just because enterprise fizzbuzz is the peak point of software doesn’t mean that you should build everything in the most complex way possible. If a small script will do, do that instead. If you build a massive project for a small task, it’ll be a nightmare to get back to it later. Let things grow naturally as needs arise.
Programming language choice
See this lovely blog post on how well Claude Sonnet 4.5 does across different languages: https://vivsha.ws/blog/stress-testing-claudes-language-skills
I haven’t tried agentic coding with languages I’m unfamiliar with so far, so I cannot comment on it. Generally the consensus seems to be “use the language that fits the project best, even if you’re currently bad at writing that language, if you’re a decent reviewer that’s a good start.”.
Learning vs deskilling
This is a good paper on the topic by Anthropic, albeit with a small sample size and without agentic coding: https://www.anthropic.com/research/AI-assistance-coding-skills
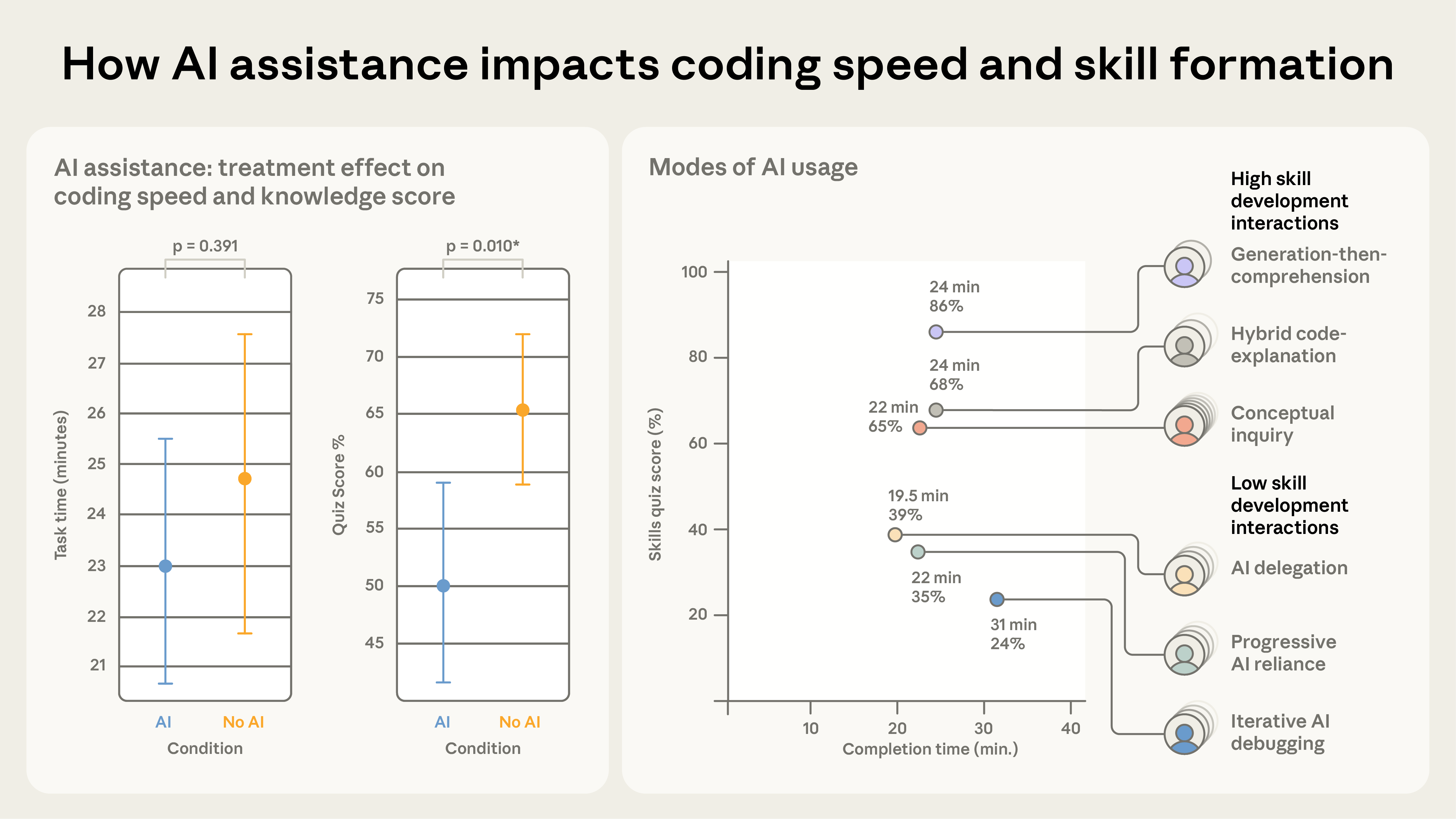
Here’s how I read it:
- People without LLM usage completed the task in ~25 minutes on average.
- Those using their time to LLMs ask questions and build comprehension scored as well if not better on the quiz vs no LLMs (No LLM: 65%, “High skill development interactions” LLM: 86%, 68%, 65%).
- Those who delegated the task to LLMs but didn’t ask questions finished notably faster, but learned less. Those who relied poorly on it learned the least and took the longest.
So, it should be possible to use an LLM to both get work done and improve your understanding. Do that :)
With agentic coding you spend even less time coding than in this paper, so that should leave you more time to learn about the output.